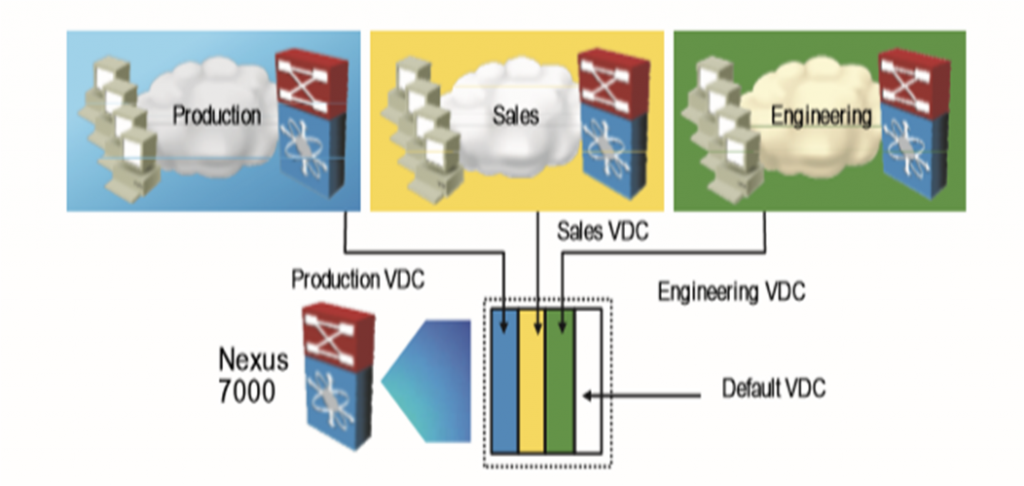
یعنی یک سوئیچ فیزیکی به چند سوئیچ logical مجزا تقسیم شود و این ویژگی در Nexus 7000 می باشد.
به جای اینکه چند دیوایس جدا بخریم که هزینه بر است، روی یک سوئیچ فیزیکی چند تا VDC جدا ایجاد کنیم که این ها از هم مستقل اند.
مانند: Production VDC | Sales VDC | Engineering VDC
کاربردها در VDC
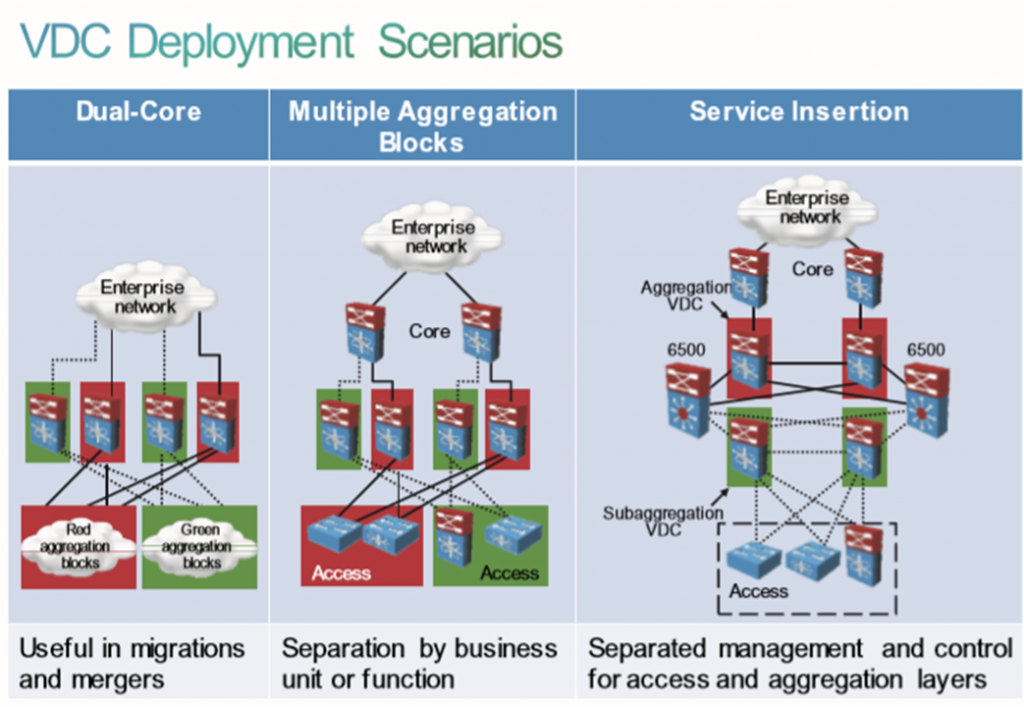
1- در جایی که چند تا core داریم.
2- برای جداسازی چندین aggregation module:
Aggregation های مختلف به یک core وصل شوند
3-برای جداسازی چندین core module.
یک لینک سوئیچ سرویس ماژول ها به صورت فیزیکی به ساب ماژول VDC / ، ماژول پایین تر و لینک دیگر به صورت فیزیکی به ماژول VDC / بالاتر متصل می کنیم. ترافیک عبوری دیتاسنتر از سرویس ماژول عبور می کند و می توانیم آن را مدیریت کنیم.
Default VDC
جایگاه: سوئیچ Nexus 7000< Console > به صورت دیفالت داخل VDC هستیم.
VDC دیفالت، علاوه بر اینکه VDC است، مدیریت بقیه VDC ها را بر عهده دارد. مثل کنترل ریسورس ها. مانند: کنترل، allocate کردن پورت به VDC ها، جابه جایی ترافیک. این VDC را نمی توان پاک کرد.در SUP2 / SUP2E این Admin VDC جایگزین VDC شد. که دیگر نمی تواند نقش یک VDC عادی را داشته باشد. صرفا مدیریتی. ایجاد و پاک کردن VDC، کنترل ریسورس ها مانند: forwarding، allocate کردن پورت، عدم داشتن routing table، mac table و feature L2/L3 به طور کل می توانیم، 4 تا VDC روی این مدل سوئیچ داشته باشیم.
ساختار VDC
وقتی یک سوئیچ فیزیکی را به چند VDC تبدیل کینم، از لحاظ فیزیکی مثل، Kernel، infrastructure و سخت افزاری مثل CPU و Memory با هم share اند اما از لحاظ سرویس های layer 2 و layer 3 از هم مجزا هستند.
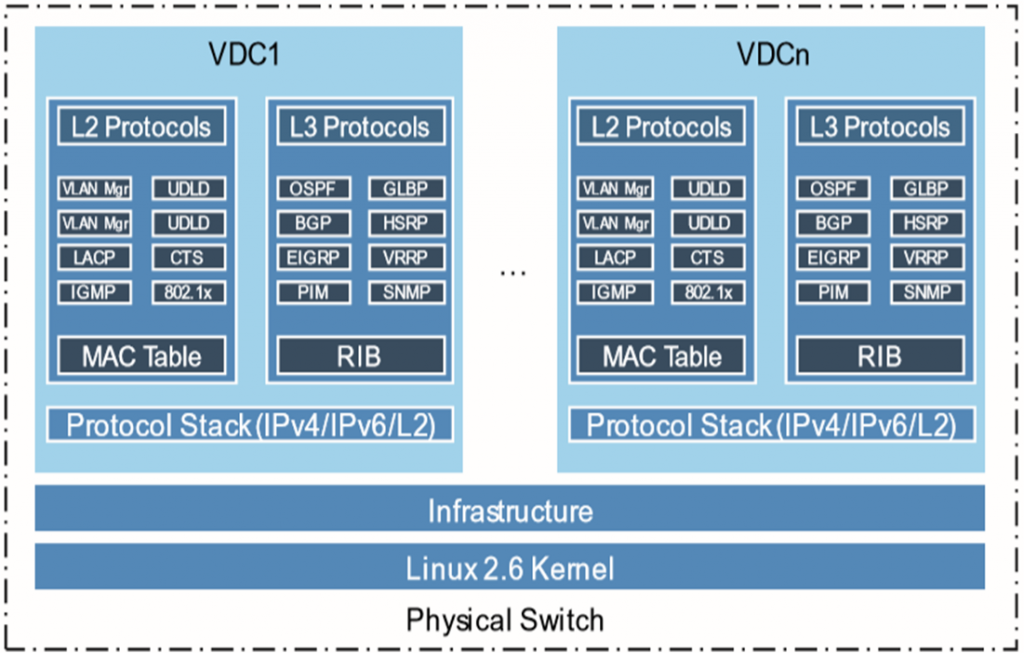
عدم اختلال VDC ها نسبت به یکدیگر
در هر VDC، V-Lan ها VRFهایی است که مستقل از VDC دیگری است. ارتباط بین هر VDC از طریق interface های بیرونی با رفت و برگشت ترافیک هر VDC، process های خاص خود را دارد که crash کردن یکی باعث اختلال در دیگری نمی شود.
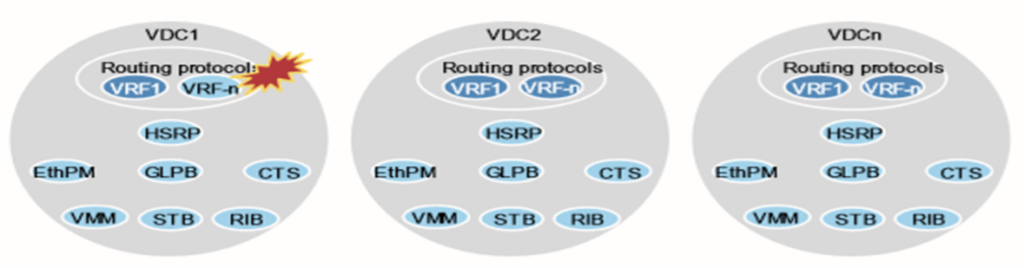

انواع resource ها در VDC ها
1- Global resource :
resource اختصاص یافته به تمامی VDC ها. مثل: NTP، CoPP
2- Shared resource: بین VDC ها به اشتراک گذاشته می شود. مثل CPU، Memory و دو نوع اینترفیس داریم که می توانند shared شوند. Management و storage VDC اگر به واسطه یک VDC، کل منابع گرفته شود و CPU درگیر شود و بقیه VDCها بی نصیب بمانند. در Nexus، 6.1 به بالا، برای هر VDC، priority تعریف کنید،پس آن VDC که بیشتر است در به کارگیری CPU و process ها اولویت بیشتری دارد.
3- Dedicated resource: هر VDC، interface، V-Lan و … مخصوص به خود را دارد.
نکته: resource template جدولی است که مشخصات resource ها از جمله:هر VDC چه قدر max و min ها را در اختیار دارد.
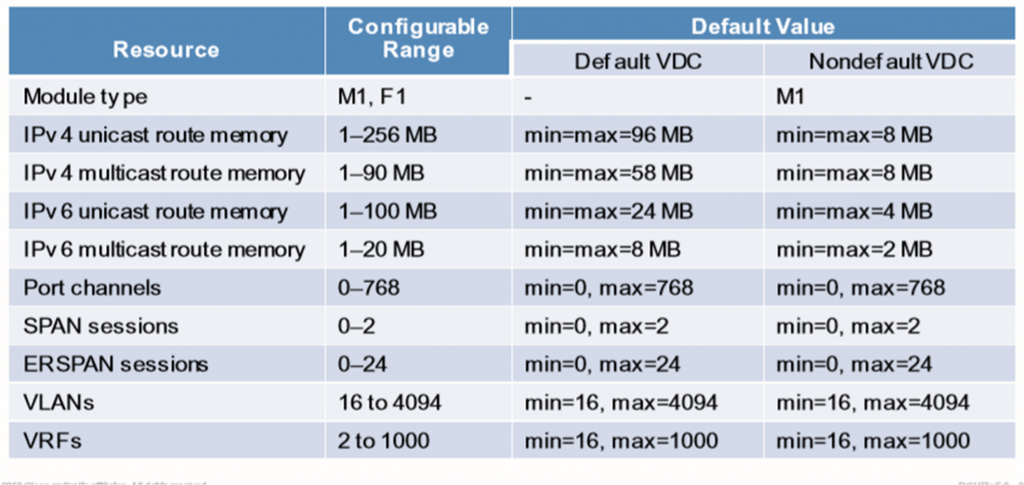
تنظیم حجم resource ها
وقتی VDC تعریف می کنید، هر کدام از آن ها ممکن است حجم resource های متفاوتی داشته باشد.
در این شکل سه VDC داریم که سایز routing table و access control entry (ACE) در آن ها متفاوت است. دو تا VDC که Resource های بیشتری استفاده می کنند در یک ماژول نمیگذاریم و TCAM دچار محدودیت مثلا در اینجا پورت VDC شماره 20 را به ماژول 10 و 30 ، allocate می کنیم. در همه ی ماژول ها پورت allocate به VDC 20


High Available Policy – (HA-Policy)
NK-7000 دو عدد SUP دارد. در صورت خراب شدن نوع Single-SUP آن یا crash کردن VDC، عکس العمل سوئیچ در چنین شرایطی را گویند:
برای VDC های غیر دیفالت، 4 نوع policy داریم.
1- restart: دیلیت کردن و دوباره ایجاد کردن و برگرداندن کانفیگ VDC (single-dual)
2- Bring down:
VDC را از کار انداختن تا زمان اکتیو کردن توسط ادمین (single-dual)
3- reload: با لود کردن، کلیه VDC ها از کار می افتند (single)
4- switchover: تعویض جای access (dual)
برای VDC های دیفالت، policy قابل تغییر نیست.
reload:
(single)
switchover:
(dual)
انواع مدل cabling
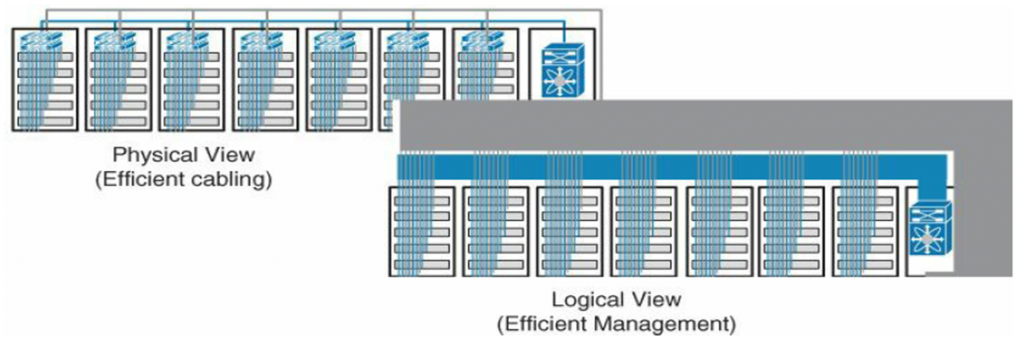
1- روش end / middle of row: در دیتاسنتر، یک rack انتها یا وسط داشته باشیم و همه ی سوئیچ های access را داخل آن بگذاریم. همه سرورها توسط کابل connection بگیرند، و این کابل ها داخل سوئیچ access جمع شوند. حجم زیاد کابل، management سوئیچ access را دشوار می کند و مشکل cooling.
2- روش top of rack: بالای هر rack سوئیچ access بگذاریم و سرور های هر rack را به همان سوئیچ access بالای rack متصل کنیم. کابل ها از rack بیرون نمی آیند و فقط از rack، یک کابل به switch aggregation )سوئیچ آخری) متصل می شود. مشکلات روش قبل را ندارد. ولی مدیریت تعداد زیاد سوئیچ ها دشوار است.
Fabric Extended
Fex: این سوئیچ ها در بالای رک قرار دارند، fex هستند. Extend Fabric شده ی سوئیچ های access اند. بالای rack1 تا rack n 2 تا سوئیچ می گذاریم. سرور های همان rack را به سوئیچ های همان rack متصل کرده ایم. از هر rack، 2 یا 4 کابل بیرون می آید که به rack مرکزی به سوئیچ های access اش متصل می کنیم. این fex ها روی سوئیچ access مدیریت می شوند. معادل این است که سرور ها به سوئیچ های access متصل شده.
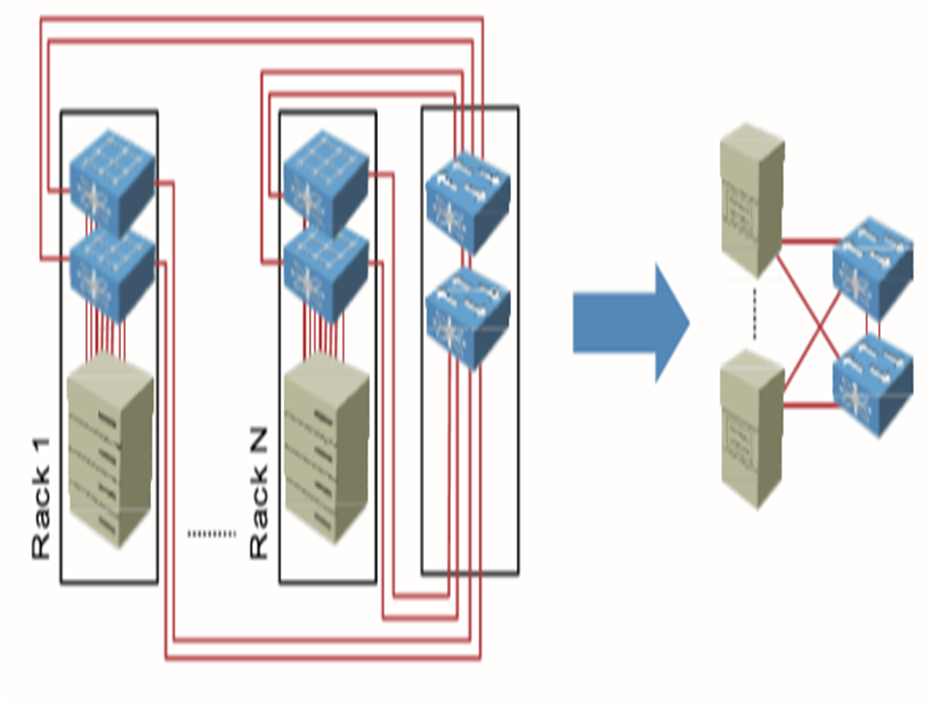
مدل های پیاده سازی Fex
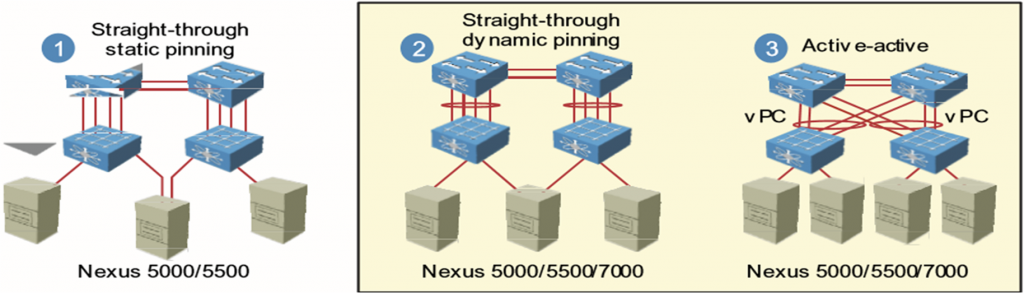
Straight-through با استفاده از static pinning: هر fex توسط 1،2 ، 4 و 8 کابل به یک switch access متصل است تا تمام ترافیک های سرور را aggregate کند و به parent switch برساند. uplink هایی که بین fex و سوئیچ قرار دارند،statically، bine می شوند به پورت های متصل به سرور.
Straight-through با استفاده از dynamic pinning: هر fex به یک parent switch متصل است. لینک بین fex و switch access ، port channel می شود. (یک لینک logical داریم به جای چندین لینک)
Active-Active با استفاده از vPC: دو سوئیچ access را با هم vPC می کنیم و هر fex به دو تا parent switch متصل است پس پورت هایی که به دو تا parent switch وصل اند، با هم port channel می شوند.
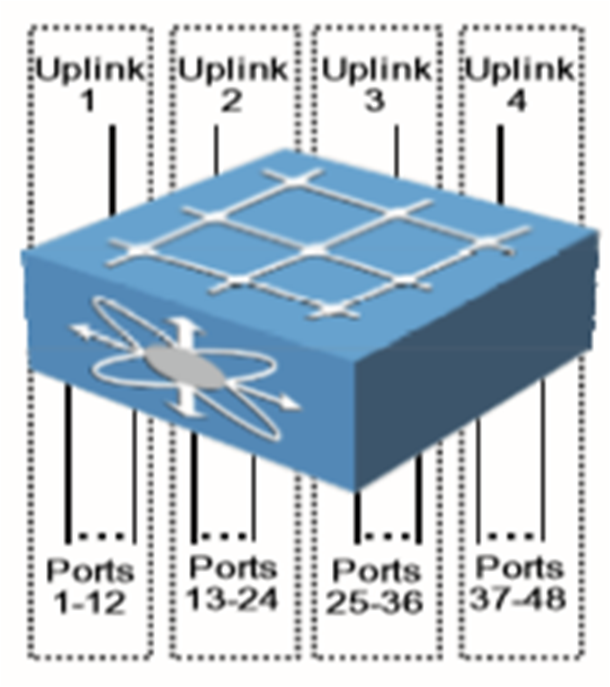
Static pinning
مثال: 4 کابل بین fex و access و 48 پورت روی fex داریم که هر 12 پورت به یکی ازuplink ها bine می شود. اگر یک یا چند uplink قطع شود، downlink ها نیز قطع می گردند و به طور اتومات، هر 12 پورت shutdown میشوند و سرور هایی که به 12 پورت متصلند،مجبورند ترافیک را از طریق fex دیگر بفرستند. اگر سروری، single-homed باشد، با قطع اتصالات، شبکه سرور ها قطع میشود.
معایب: با قطع لینک و یا هر کدام از سوئیچ ها، اتصال از بین می رود.
Dynamic pinning
مثال: در اینجا 48 پورت داریم و هر 48 پورت به 1 لینک (port channel) bine می شود. هر کدام از لینک های فیزیکی قطع شود، port channel، down نمیشود (مگر اینکه هر 4 تا با هم down شوند) پس single-homed اتصال را از دست نمی دهند و dual-homed مسیرشان جابه جا نمی شود.
با قطع switch access یا fex مقاوم نیست.

نکات تکمیلی این مبحث
Nexus 7000، از مدل static pinning و active-active fex پشتیبانی نمیکند. (به این دلیل که بخاطر ویژگی های این سوئیچ، مثلا دارای 2 sup، 6 power و …( اگر parent switch، fail شود سرورهای single-homed دچار مشکل نمی شوند.
ولی روش dynamic pinning را پشتیبانی می کند.
Port channel و vPC
Port channel: از یک سوئیچ به سوئیچ دیگر چندین لینک ایجاد کنید. این لینک ها را با هم aggregate کنید.اگر یک لینک port channel شود، بین دو سوئیچ یک لینک logical خواهد شد. هر لینکی قطع شود، ارتباط از بین نمی رود.
مزیت: افزایش پهنای باند (4 برابر با 4 لینک) – برقراری ارتباط
vPC: از یک سوئیچ به چندین سوئیچ، چندین لینک ایجاد کنیم، چون چندین سوئیچ با هم aggregate می شوند و یکی به نظر می آیند، سوئیچ پایین و بالا بین تمام لینک هایش، port channel ایجاد می کند.

کاربرد های vPC
1- Dual-uplink layer 2 access:
switch access به دو aggregation وصل است.به جای اینکه STP یک سمت را بلاک کند، دو تا aggregationرا به هم vPC می کنیم، یکی به نظر می رسند و بلاک نمی شوند. تمام لینک های access به aggregation vPC خواهند شد.
2- Server dual-homed: از یک سرور به 2 سوئیچ access متصل ایم. دوتا سوئیچ access را با هم vPC می کنیم. در اینصورت سرور تصور میکند دو تا لینک به یک سوئیچ متصل است. پس می تواند لینک ها را با هم vPC کند.
3- Active-Active fex:گاهی fex را به دو parent switchوصل می کنیم. از تصور fex، این دو یک سوئیچ اند و لینک های سمت fex را vPC می کنیم.
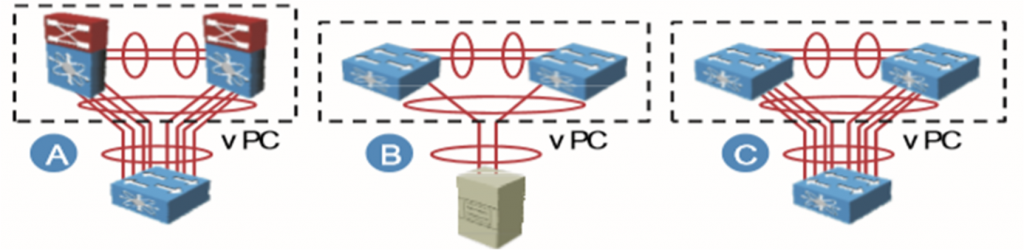
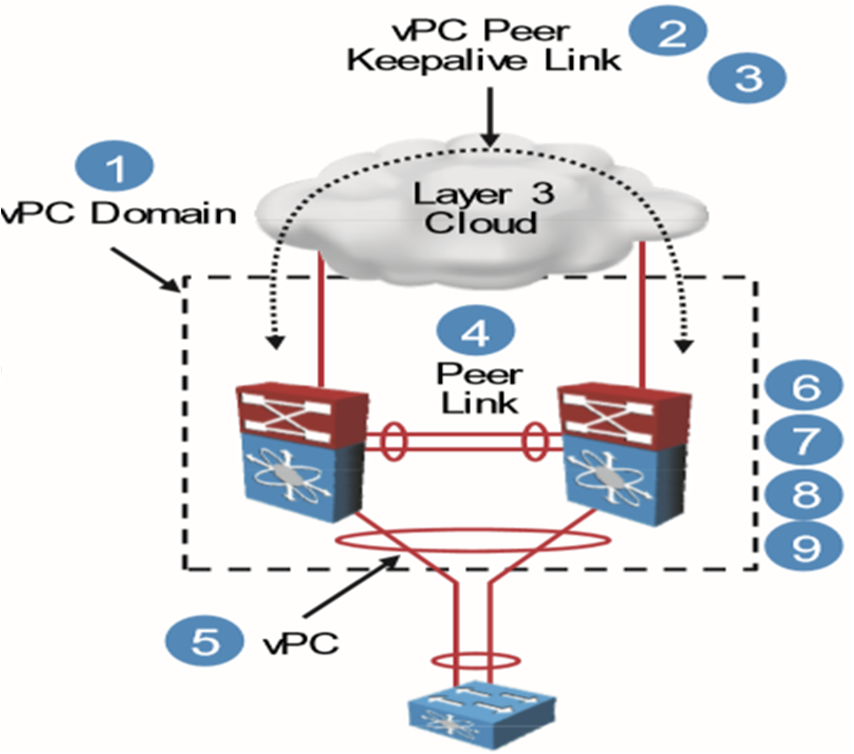
معماری vPC
vPC: پورت چنلی که لینک هایش روی سوئیچ های مختلف قرار گرفته است.
vPC peers:دو سوئیچ را به عنوان vPC domain تعریف کنیم(فقط 1 vPC).
vPC peer link: حداقل دو لینک بین سوئیچ ها (جابه جایی ترافیک کنترلی).
Cisco fabric services:کانفیگ روی سوئیچ های نکسوس توسط این feature روی بقیه روی دیگر سوئیچ ها کپی می شود.
vPC peer keepalive link: دو سوئیچ از یک مسیر، غیر از مسیر peer link ،active بودن همدیگر را چک کنند.
vPC member port: هر دو تا پورت متصل به سوئیچ پایینی.
Orphan device: دیوایسی که جزو vPC قرار نگیرد.
Orphan port:به پورت های orphan device گویند.

مراحل کانفیگ vPC
1- تعریف domain (فقط یک دامین)
2- اولین کانفیگ مربوط به peer keepalive link است (مطمئن شویم لینک اش روی peer link رد نمی شود)
3- کانفیگ peer link (حداقل دو تا لینک را با هم port channel کنیم.
4- کانفیگ کردن vPC، دو تا لینکی که از سوئیچ پایین به دو تا سوئیچ بالا وصل است را vPC می کنیم.
5- بهینه سازی vPC-peer gateway
6- بهینه سازی vPC-peer switch
7- Verify کردن vPC
8- Verify کردن پارامترهای vPC